


Decoding Emotions
What Word-Emotion Lexicons Can Teach us About Language

Introduction
Welcome to Better Know a Dataset!
For the first dataset to christen this blog, I will study the NRC's Word-Emotion Association Lexicon. As its name suggests, this lexicon is “a list of English words and their associations with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive).” In today’s post, I will explore this lexicon with a view toward seeing what we can learn about the emotional properties of language, and how this dataset can be used in research. As a preview of what’s to come, I first study the distribution of emotions in English, including techniques for extracting the core dimensions of emotional classification. I then feature two examples of how to use these lexicons to understand text sentiment. Finally I compare word-emotion lexicon approaches to those using LLMs.
To generate this word-emotion dataset, the authors manually crowdsourced responses, i.e. they took a list of 140,000 words and polled participants on Amazon’s Mechanical Turk with such questions as “How much does the word [] evoke or produce the emotion []?” The answers were collected and aggregated into a dataset of word×emotion with a “1” indicating presence of that emotion and a “0” otherwise. A preview of some words from the dataset are given in Fig 1:

Emotions…
While the primary use-case of an emotional lexicon is to tag the sentiment of other texts, I wanted to start with a fairly simple tabulation exercise to see what the lexicon itself implies about the emotional distribution of our language. For example, if one were to randomly select a word from English, how common is it for that word to have any emotions attached, and which emotions are most (least) frequent?

In Figure 2, I begin by plotting the frequency of various emotions in our dataset. Consider the navy blue bars, which show the simple proportion of the lexicon coded with each emotion. The first thing to notice is that it is more common for a word to have no emotion than to have (some) emotion. Of the 140,000 words in the lexicon, a little over half receive a 0 on every emotion. This is probably what we would expect — most nouns are simply descriptive, after all, and it is probably suboptimal to have a language that is overly laden with emotion. Among emotional words, the second thing to notice from the figure is that frequency favors negatively-coded words. This is true not just in the literal sense — with “negative” more frequent than “positive” — but also in a more semantic sense, with “fear”, “anger” and “sadness” more common than “joy” and “surprise”.
All else equal, this suggests our language is more negative than positive. But an alternative interpretation is that there are simply more words involving, e.g., fear than surprise. To avoid capturing this size effect, I thus calculate a weighted frequency, where I take the average proportion weighted by the (log) frequency of that word in the English language. These frequency-weighted averages are plotted in the light blue bars. Somewhat surprisingly, the results are mostly unchanged. The lesson here is that the English language is more negative than positive, both in a number-of-words sense and in a word-frequency sense. More broadly, the number of words to describe an emotion seems roughly independent from the frequency of those emotion-specific words.
…and Co-Emotions
A useful feature of the word-emotion dataset is that words are not limited to a single emotion: a word can have multiple emotions attached to it. But are most words associated with multiple emotions or just one? And to the extent words are associated with multiple emotions, is there anything special about the word (or the emotion)?
To answer these, I begin by plotting a simple histogram of emotions per word. Not surprisingly, most words don’t conjure up any of the listed emotions. Zero emotion words include “ecumenical”, “role”, “retired”, “weave”, and “screwdriver”. (”Dissertation” is also coded as having zero emotions, which I’m not sure I agree with). From there, the number of emotions per words tends to decrease: 1 emotion words are more common than 2 emotion; 2 more than 3; etc.

There are two words in the dataset with all 10 emotions: “feeling” and “treat”; 1 with 9 emotions (”weight”), and a handful with 8 (”celebrity”, “intense”, “obliging”, “opera”, “supremacy”, and “vote”). Some more examples of words with varying numbers of emotions are given in the table below.

I next consider which emotions tend to occur together in a word. To visualize this, I construct a plot showing the correlations of emotions across the words:

Darker red squares indicate positive correlation, i.e. words tend to have both emotions. We see that joy and anticipation go together; as do fear and anger, and trust and anticipation. Other combinations are much rarer: fear and joy, joy and disgust, trust and negative. I was curious to see some examples of these rarer combinations; I provide some cases below:

I had assumed that many of the words on these lists would be ones with multiple meanings — e.g. “execution” as capital punishment vs. “execution” as implementation. To the contrary, the words in the table seem to reflect ones where the emotion depends on the perspective of the agent. “Powerful” is a joyful word if you’re the one in power, but disgusting if you’re not. “Endless” is joyful when referring to a buffet, but infuriating when it refers to a flight delay. Similar rationale probably applies to diagnosis, servant, armed, abundance, etc.
What’s in an Emotion?
Strong positive or negative associations across emotions suggests that such a granular level of classification may not be necessary. Put differently, if “anger” and “disgust” are so commonly found among the same words, is there much to be added by separately crowdsourcing these emotions? Or are we really just capturing some broader notion of “good” vs “bad”? Fortunately, we can quantify the answers to these questions using a tool known as principal component analysis (PCA).
A full description of PCA is beyond the scope of this post. But roughly speaking, it asks how much of the variation across words we can explain if we condense our dataset by combining emotions down to a fewer set of variables. This smaller set of variables is some linear combination of emotions — e.g., maybe it combines “anger” and “fear”. The plot below (known as a “scree plot”) shows how much of the variation in words we can explain through these components, presented in order from those components that explain the most variation (PC1) to those that explain the least (PC10). The columns show the percent of variance contributed by each dimension, while the line tracks the cumulative variance explained. As we increase the number of components, we of course explain more of the variation (at all 10 variables, we perfectly obtain the original dataset, i.e. explain all the variation in emotion).
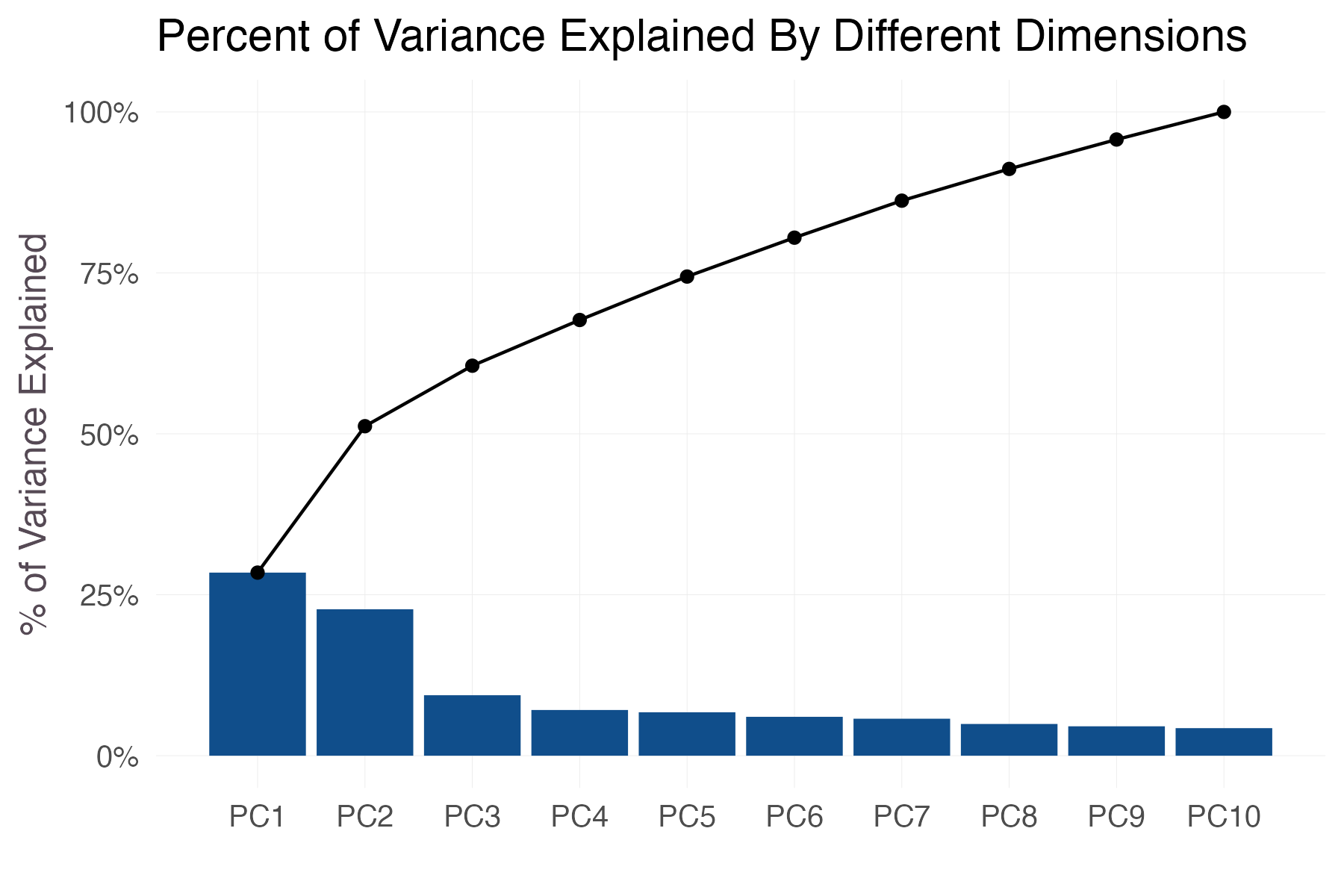
With just two principal components — i.e., two linear combinations of emotions — we can explain more than 50% of the variation in the dataset. So about half of all emotion is really just captured by two latent characteristics in the space of the emotions. After those first two, it’s a slow but steady to march to explain the remainder of the variation.
What exactly are these two latent combinations that explain so much of the cross-section in emotion? As a purely numerical exercise, PCA does not always give an interpretable answer. But we can make progress on this question by plotting how exactly these latent variables — the so-called “principal components” — combine different emotions. In the plot below, I look at the weights on each emotion for the first two principal components:

Consider the first principal component, in the left panel. It loads positively on “anger”, “disgust”, “fear”, “negative”, and “sadness”, and it loads negatively on “anticipation”, “joy”, and “positive”. We can thus probably interpret this factor as a “good” vs “bad” characteristic. In other words, 25% of the emotional variation across words is really just “good vs bad”. Now consider the second principal component, in the right panel. This PC is a little more interesting: it loads positively on every emotion (and a little more heavily on anticipation, joy, etc). PCs that load positively on every variable are usually thought of as “common factors”, i.e. it probably captures the very fact of having an emotion (recall that most words don’t have any emotions). So the second principal component says that about another 25% of variation in the emotional character of words is whether they have any emotion at all.
In principle, one can run through the full list of PCs and try to figure out the interpretation of that dimension. But as you you may have noticed from the previous paragraph, this is as much art as it is science, and will generally get more difficult as we move to PCs that explain less and less variance. [For example, I have looked at PC3 and can only venture a guess as to what it’s capturing; feel free to take a look yourself].1
Parsing Text
Aside from investigating the semantic overlap of words, what is this dataset useful for? The obvious candidate is taking large chunks of text and classifying them across a range of emotions. The NRC’s website gives many such examples: Who is the angriest character on Seinfeld? How do the emotions of Trump’s Android tweets compare to his iPhone tweets? Can we predict stock returns by analyzing the sentiment of 10ks? This is a long literature with countless applications. But to illustrate this approach briefly, I thought I would give two examples: (1) reading the Bible (2) tracking the news.
Reading the Bible
I downloaded the text of the King James Version of the bible using the sacred package in R. For each verse, I summed the number of words associated with each emotion. Consider, for example, Ezekiel 25:17 (bonus points to those who get the reference).
“And I will execute great vengeance upon them with furious rebukes; and they shall know that I am the LORD, when I shall lay my vengeance upon them.””
Many of these words are “stop words” that have no emotion (”And”, “I”, “will”, etc). Condensing down to the words that are featured in the emotion dataset, we obtain the following table:

Not surprisingly, the predominant emotions are “anger” and “negative”. Vengeance gets counted twice (because it appears twice); and some words (like “great”) are strangely not featured at all in the NRC lexicon.
We can apply this approach to the entire bible, and calculate the percentage of each book that features each emotion.2 Since as we saw in Fig. 2, certain emotions are unconditionally more frequent, I subtract the across-book average emotion to get the relative emotion of each book, and then normalize by the standard deviation.

The way to read this graph is to take an emotion and look across the rows (books) to get the relative score of that book on that emotion. Darker red indicates that that book is more likely to feature that emotion than other books. For example, compared to the rest of the Bible, Leviticus has more “disgust”-coded words, while Genesis has fewer negative words (and many more “joy” words). Numbers is pretty close to average in most of its emotional valence. Deuteronomy has a lot of fear. We can also plot the books of the bible in the reduced-dimension principal component space; there, Leviticus has highest loading on PC1 (has the most “bad” emotion according to our interpretation) while Genesis has the lowest loading (the most “good”).
Newspaper Headlines
In a similar exercise, I move to classify the news. I use the “A Million News Headlines” dataset from Kaggle. These are Australian news headlines, not US headlines, but will serve for the purposes of illustration. As with the biblical dataset, for each quarter I count the fraction of words association with each emotion. I then plot the corresponding series:

There is some interesting time series variation. “Sadness” went way down during the lockdown (I guess the lexicon doesn’t have “Coronavirus”, and there wasn’t much else happening in the world). There are also several low frequency trends, like the decline of “angry” and “anticipation” words in headlines. Unfortunately I don’t know enough about the Australian scene to comment much further.
What About LLMs?
Word-emotion association is fundamentally an exercise in natural language processing (NLP). No conversation about NLP is complete without thinking about the role of LLMs like ChatGPT. For example: does this lexicon add anything relative to ChatGPT? And are there things ChatGPT is useful for that this lexicon is not?
To begin addressing these questions, I task ChatGPT with a similar crowdsourcing exercise: to classify words on a 0/1 scale according to the 10 listed emotions. In particular, I use the following prompt:
I will give you a word. I want you to score it on the following 10 emotions: anger, anticipation, disgust, fear, joy, negative, positive, sadness, surprise, trust.
All scores must be 1 or 0, but a word can have as many 1's as you deem appropriate. Please return your answer as a csv, with no explanation.
The word is: [___]
Using this approach, for example, I can construct ChatGPT’s corresponding version of the Ezekiel 25:17 table:

Like with the NRC lexicon, ChatGPT’s interpretation of this passage loads heavily on “anger’ and “negative”. But there are some important differences. ChatGPT sees a role for fear and anticipation, where NRC does not.
To inspect the differences in word-level interpretation more systematically, I use the OpenAI API to score 2500 randomly chosen words from the NRC Lexicon, and I compare the scored emotions across approaches. The primary difference is that ChatGPT loves assigning emotions to words: just 11% of words are emotionless according to ChatGPT, compared to 53% of the corresponding NRC words. Examples of NRC-emotionless words to which ChatGPT assigns emotions are “balsamic” (positive and anticipation according to ChatGPT), “shovel” (negative for some reason), “slick” (negative and positive), and “masquerade” (anticipation, surprise, joy and positive). There is also a small sample of words for which ChatGPT assigns no emotion and NRC does: aga, boilerplate, lumpy, margin, etc.
What about at the intensive margin? To focus on within-score comparison, I drop emotionless words and compare the frequencies among words with some emotion:

Even within “emotional” words, ChatGPT is more likely to assign emotions across the board. The two approaches do seem to largely agree on the sentiment classifications — negative vs. positive — but differ markedly across several other emotions. The most striking difference is the large role of “anticipation” in ChatGPTs classification. Some of these “anticipation” words make sense to me (watch, poker, maternity) while others do not (sultan, radiate, magnet).
In a similar spirit, I run regressions for each emotion of the ChatGPT score on the NRC score. The coefficients in these regressions capture similarity in scoring, namely, they give the probability ChatGPT assigns a given emotion to a word given that NRC has scored it with that emotion. The coefficients range from 71% at the high end (”negative”) to 30% at the low end (”surprise”). These are somewhat lower than I would have expected: we would hope that it’s more likely than not they agree on each emotion (coefficient > 50%). However, despite these differences, the first several principal components of the two lexicons are nearly identical, suggesting that both approaches agree on the most important dimensions of emotion, if not each individual emotion.
A second difference between lexicons and LLMs is that LLMs can understand context. For example, consider the sentence “I will never hurt you”. A pure lexicon (”bag-of-words”) approach will attach negative emotions to “hurt”, without using the context — namely, negation — to update its interpretation. By contrast, LLMs “understand” this entire sentence and will interpret it positively. This suggests an alternative approach that uses an LLM to classify the entire sentence. For example, I can simply feed Ezekiel 25:17 to ChatGPT and ask it to give me on a scale from 0:1 how much that sentence is associated with anger, fear, joy, etc. ChatGPT’s response: anger (0.8), anticipation (0.7), disgust (0.6), fear (0.8), joy (0.1), negative (0.9), positive (0.1), sadness (0), surprise (0), trust (0.7).3
Together these might seem like ChatGPT is unconditionally better.4 I think this is largely correct, with the caveat that in its current form, it is infeasible to call ChatGPT on very large datasets. For example, to obtain the emotional report card on all verses in the Bible would require 31,000 queries to ChatGPT. Directly querying the ChatGPT web interface is too slow (even if done in chunks), while the OpenAI API will automate this process but charge money per query. So for (very) basic sentiment analyses of (very) large texts, lexicons such as NRC may have a slight advantage.5
Conclusion
In this blog series, we will try to end every post with “Takeaways” that summarize the main findings (both methodological and substantive), and some “Open Questions” that may be interesting to pursue. In that vein…
Takeaways
A little over half of words have no emotions, and negatively coded emotions tend to be more frequent in the English language than positively coded emotions. Certain emotions (anger and fear) are much more likely to co-occur than others (joy and disgust). Words that have multiple emotions (especially seemingly contradictory emotions) tend to be those that depend on perspective (e.g. “powerful”, “servant”, “confess”).
PCA is a useful tool for understanding how many “dimensions” there are to a dataset, though the interpretation of what these dimensions mean can be tricky. Using PCA, we showed that roughly half of the variation in the emotional character across words can be explained by two principal components, one of which seems to proxy a “good vs. bad” characteristic, and one of which proxies an “emotional vs. non-emotional” characteristic.
Lexicons allow for “bag-of-words” type approaches to classifying the sentiment of texts, which can be useful for comparing different texts (e.g. books of the Bible) or tracking evolution of sentiment over time (e.g. news headlines). The challenge with these approaches is that (a) they ignore context (b) they don’t always agree with other approaches (e.g. LLMs). The challenge with LLMs is that they can be more difficult to employ on large text corpuses.
Some Open Questions
A cool feature of the dataset is that it has lexicons for many different languages. This opens up several interesting analyses. For example, how does the frequency of emotions, and the frequency with which emotions co-occur, vary across languages? Are there words that have the same translation in English, but very different emotional scores (and why)? With German — a language famous for its compound words (”schadenfreude”) — how does emotion co-location work within compound words?
Are there any systematic patterns to how ChatGPT classifies a word’s emotions vs how the crowdsourcing does it? What are these patterns? For example, does ChatGPT do particularly badly with adjectives? Or with archaic words? Does it bundle together certain emotions more closely?
We saw certain cases where context matters (e.g., when a bad word is negated). Thinking more broadly across texts, with what type of texts does a “bag of words” approach that ignores context do very poorly? E.g. if we take: 10ks, poems, news headlines, emails, etc, which of these corpuses has the largest gap between the “bag of words” approach and the context-cognizant approach?
Here is PC3. My guess is that it has something to do with certainty (loading negatively on “anticipation” and “surprise”; positively on “trust” and “positive”)

.
I only show the first 5 books for exposition. However, I computed these measures for every book in the bible. The most positive book was the Book of Esther.
I was curious why ChatGPT gave Ezekiel 25:17 such a high score for “anticipation”, so I asked ChatGPT to explain itself. Its answer: “In the sentence, there is an element of anticipation conveyed through the phrase "shall know," suggesting an expectation or anticipation of future events. While it's not the primary emotion expressed in the sentence, it still carries some weight in the overall context”.
Another advantage of LLMs is that they can automatically “lemmatize” a dataset. For example, a lexicon will not generally have separate entries for “attack”, “attacks”, “attacking”, “attacked”, etc, so the researcher has to pre-process the dataset to obtain the core word, in a way that LLMs will do automatically. Readers may have noticed this was an issue in the Ezekiel 25:17 passage: the word “rebukes” in the passage did not occur in the frequency table, since only “rebuke” (unpluralized) occurs in the lexicon.
There are two approaches to get around the challenge of feeding large texts to an LLM. One is to use an LLM on a smaller sample of text, and then using this sample, train a model to predict the LLM classification using the lexicon classification. Armed with this model, one can predict the LLM classification without having to further call the LLM. Another approach is to use a RAG (”retrieval-augmented generation”) model with an LLM. I will save a discussion of this method for a later post.
Absolutely fascinating! I can't wait for next week's Dataset!